บทที่ 13 "การสร้างแบบจำลอง"

ออกแบบทั้งโครงสร้างจบในโมเดลเดียว
ไม่ว่าจะเป็นการออกแบบแผนงานไปจนถึงการออกแบบละเอียด คุณสามารถใช้แบบจำลองเพียงชุดเดียวที่ครอบคลุมทุกข้อกำหนดด้านการออกแบบและวิเคราะห์โครงสร้าง ครอบคลุมทั้งระบบแรงตามแรงโน้มถ่วงและแรงด้านข้าง ด้วย Tekla Structural Designer คุณไม่จำเป็นต้องซื้อโมดูลเพิ่มเติม และไม่ต้องเสียเวลาไปกับการสลับไปมาระหว่างซอฟต์แวร์หลายโปรแกรมเพื่อให้ได้โซลูชั่นการออกแบบที่สำเร็จของคุณ
แนวทางปฏิวัติวงการ
Tekla Structural Designer นั้นแตกต่างจากซอฟต์แวร์วิเคราะห์แบบดั้งเดิม ซอฟต์แวร์ของเราช่วยให้คุณสร้างแบบจำลองที่ครบถ้วนด้วยข้อมูล และมีข้อมูลที่จำเป็นทั้งหมดสำหรับการวางแผนการออกแบบอัตโนมัติและจัดการการเปลี่ยนแปลงภายในโครงการ ระบบนี้ช่วยให้คุณออกแบบเสร็จเร็วขึ้นและสร้างผลกำไรได้สูงสุด
การผสานรวม BIM ได้อย่างลื่นไหล
เนื่องจากคุณสร้างแบบจำลองเดียวจากชุด ข้อมูลเดียว การผสาน BIM จึงเป็นไปอย่างลื่นไหลและมีประสิทธิภาพ ทำงานร่วมกันได้อย่างไม่มีสะดุด ประเมินผลกระทบจากการเปลี่ยนแปลงได้ทันที และนำเสนอโซลูชั่นที่มีประสิทธิภาพยิ่งขึ้นให้แก่ลูกค้า
ที่มา. www.tekla.com
การสร้างโมเดล Ensemble แบบต่างๆ
เทคนิค Ensemble เป็นเทคนิคที่ใช้โมเดล classification หลายๆ โมเดล (model) มาช่วยในการหาคำตอบ เทคนิคนี้ได้เป็นเทคนิคที่มีประสิทธิภาพสูงซึ่งพบได้จากการแข่งขันต่างๆ เช่น Netflix หรือ Kaggle ที่ผู้ชนะมักจะใช้เทคนิค Ensemble นี้ (http://mlwave.com/kaggle-ensembling-guide/) หรือในงานวิจัยต่างๆ ครับ เช่น งานวิจัยเรื่อง Bagging Model with Cost Sensitive Analysis on Diabetes Data หรือ Boosting-based ensemble learning with penalty profiles for automatic Thai unknown word recognition สำหรับในบทความนี้ผมขออธิบายหลักการของเทคนิค Ensemble แบบง่ายๆ 3 เทคนิคครับ นั่นคือ
- Vote Ensemble เป็นการใช้เทรนนิ่ง ดาต้า (training data) ชุดเดียวกันแต่สร้างโมเดลด้วยเทคนิคต่างๆ กัน
- Bootstrap Aggregating (Bagging) เป็นการสุ่มเทรนนิ่ง ดาต้า (training data) ให้เป็นหลายชุด แต่สร้างโมเดลด้วยเทคนิคเดียวกันทั้งหมด
- Random Forest เป็นเทคนิคที่คล้ายๆ กับ Bagging แต่แทนที่จะสุ่มข้อมูลอย่างเดียวก็ทำการสุ่มเลือกแอตทริบิวต์ (ฟีเจอร์) ต่างๆ ออกมาเป็นหลายๆ ชุดด้วย และสร้างโมเดลด้วยเทคนิค Decision Tree หลายๆ ต้นครับ
แต่ก่อนที่จะไปดูรายละเอียดของแต่ละเทคนิคเรามาดูเรื่องข้อมูลที่ใช้ในการสร้างโมเดลกันก่อนครับ ข้อมูลที่ใช้ในการสร้างโมเดลเราจะเรียกว่า เทรนนิ่ง ดาต้า (training data) ซึ่งจะประกอบด้วยแอตทริบิวต์ทั่วไป (หรือตัวแปรต้นในทางสถิติ) และแอตทริบิวต์ประเภทลาเบล (label) หรือ คลาส (class) คำตอบที่เราสนใจให้โมเดลทำนาย (predict) ออกมา (หรือตัวแปรตามในทางสถิติ) ข้อมูลเทรนนิ่ง ดาต้า แสดงได้ดังในรูปด้านล่าง ซึ่งในซอฟต์แวร์ RapidMiner Studio 6 แอตทริบิวต์ทั่วไปจะแสดงด้วยสีเทา และแอตทริบิวต์ประเภทลาเบลจะแสดงด้วยสีเขียว

จากรูปจะเป็นการนำเทรนนิ่ง ดาต้าซึ่งมีแอตทริบิวต์เป็นคำต่างๆ ในข้อความ email และแอตทริบิวต์ประเภทลาเบลบ่งบอกว่าแต่ละข้อความเป็นสแปม (spam email) หรือปกติ (normal email) จากข้อมูลเทรนนิ่ง ดาต้านี้เราสามารถสร้างเป็นโมเดล Decision Tree ได้ในด้านขวามือซึ่งใช้แค่ 2 แอตทริบิวต์ คือ Free และ Won เท่านั้น (ท่านใดสนใจวิธีการสร้างโมเดล Decision Tree ดูได้จากบทความ “ขั้นตอนการสร้างโมเดล Decision Tree“) หลังจากที่เรารู้จักกับเทรนนิ่ง ดาต้าแล้วถัดมาผมขอสรุปขั้นตอนในการสร้างโมเดล classification ก่อนครับ การสร้างโมเดลนี้สามารถแบ่งได้เป็น 2 ขั้นตอนย่อย ดังแสดงในรูปด้านล่าง
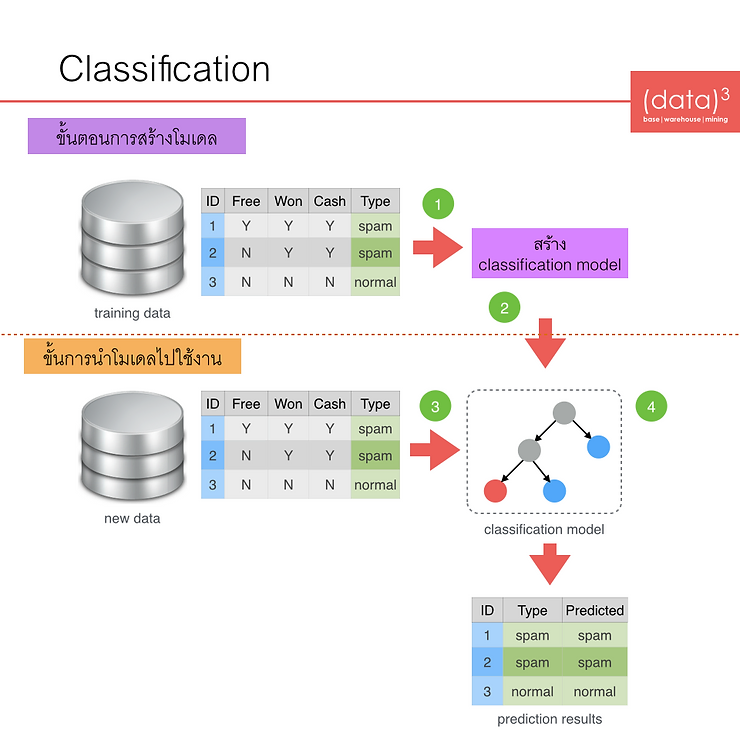
- การสร้างโมเดล (build model) เป็นการนำเทรนนิ่ง ดาต้า มาสร้างโมเดลซึ่งในขั้นตอนนี้ควรจะมีการวัดประสิทธิภาพของโมเดลก่อนนำไปใช้งาน ซึ่งการวัดประสิทธิภาพของโมเดลก็มี 3 วิธีใหญ่ ดังที่อธิบายไว้ในบทความเรื่อง “การแบ่งข้อมูลเพื่อนำมาทดสอบประสิทธิภาพของโมเดล”
- การนำโมเดลไปใช้งาน (apply model) เป็นการนำโมเดลที่สร้างได้ไปใช้ทำนายหรือหาคำตอบให้กับข้อมูลใหม่ซึ่งยังไม่รู้คลาสคำตอบ
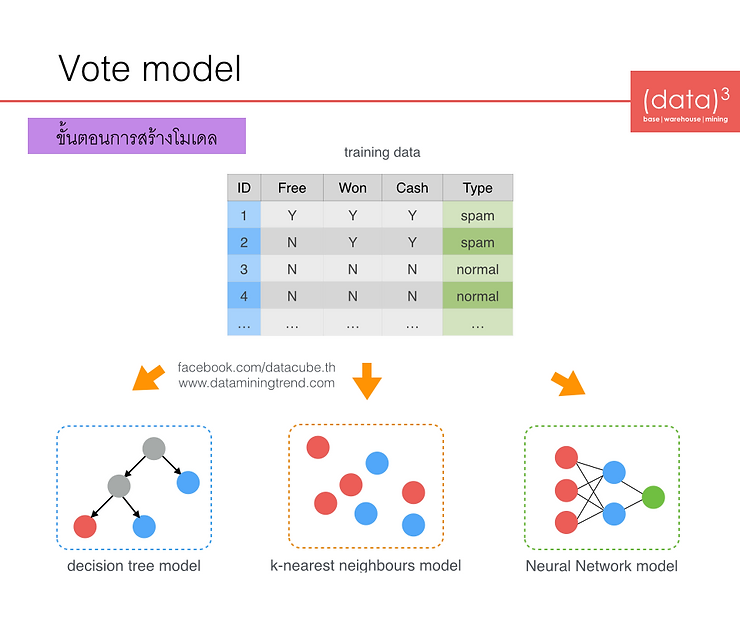
เราได้รู้จักกับการโมเดล classification กันไปแล้ว ต่อไปผมจะแนะนำเทคนิค Ensemble ซึ่งเป็นการนำหลายๆ โมเดลมาช่วยกันหาคำตอบครับ สามารถแสดง concept การทำงานของเทคนิค Ensemble ได้ดังรูปด้านล่าง

จากรูปจะเห็นว่าเป็นการนำเทรนนิ่ง ดาต้า มาสร้างโมเดลต่างๆ โดยข้อมูลเทรนนิ่ง ดาต้าเหล่านี้จะเป็นข้อมูลชุดเดียวกันก็ได้ (เช่น วิธีการ Vote Ensemble) หรือจะเป็นข้อมูลที่ต่างกันก็ได้ (เช่น วิธี Bagging และ RandomForest) หลังจากได้โมเดลมาชุดหนึ่งแล้วจึงนำไปทำนายข้อมูลที่ยังไม่รู้คำตอบ สำหรับการทำนายด้วยเทคนิค Ensemble ซึ่งมีหลายๆ โมเดลนี้ แต่ละโมเดลก็จะให้คำตอบออกมา ในขั้นตอนสุดท้ายเราจะต้องนำคำตอบเหล่านี้มารวมกันเพื่อดูว่าคำตอบไหนเหมาะสมที่สุด โดยอาจจะใช้วิธีการโหวต (vote) เลือกคำตอบที่ตอบตรงกันมากที่สุดก็ได้ครับ หลักการสร้างโมเดล Ensemble คือโมเดลที่สร้างควรจะมีความหลากหลายเพื่อให้ทำนายข้อมูลแบบต่างๆ กันได้มาก การสร้างโมเดลที่หลากหลายนี้ อาจจะทำได้โดยการใช้เทคนิค classification หลายๆ ประเภท หรือ การสร้างเทรนนิ่ง ดาต้า ที่มีลักษณะต่างๆ กัน เช่น มีตัวอย่างต่างๆ กัน หรือมีแอตทริบิวต์ต่างๆ กัน ผมขอสรุปวิธีการสร้างโมเดล Ensemble 3 แบบใหญ่ดังนี้
1. Vote Ensemble
วิธีการนี้เป็นการนำเทรนนิ่ง ดาต้าชุดเดียวกัน แต่เพื่อให้โมเดลมีความหลากหลายมากขึ้นจึงเลือกที่จะสร้างโมเดลด้วยเทคนิค classification ที่ต่างกัน ขั้นตอนการสร้างโมเดลแสดงได้ดังรูปด้านล่าง ซึ่งใช้ 3 เทคนิคที่ต่างกัน คือ เทคนิค Decision Tree, เทคนิค K-Nearest Neighbours (K-NN) และเทคนิค Neural Networks
หลังจากที่สร้างโมเดล Ensemble ด้วย 3 เทคนิคได้แล้ว ขั้นตอนถัดไป คือ การนำโมเดลที่สร้างได้ไปทำนายข้อมูลใหม่ ดังแสดงในรูปด้านล่าง
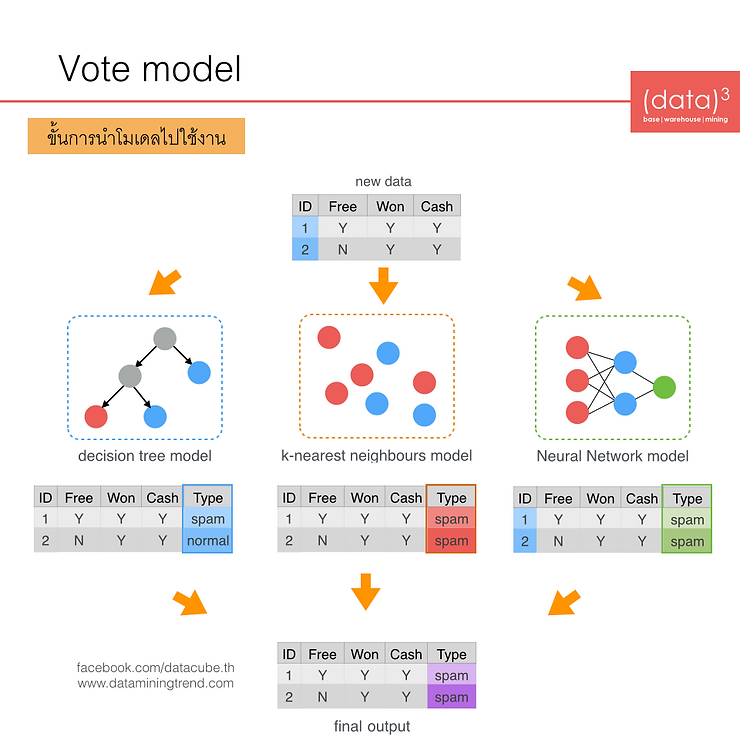
จากรูปจะมีข้อมูลใหม่ (new data) ที่ยังไม่รู้คลาสคำตอบ 2 ตัวอย่าง (example) ซึ่ง
- โมเดล Decision Tree (โมเดลที่ 1) ทำนายคำตอบออกมาว่าข้อมูลใหม่ตัวอย่างที่ 1 เป็น spam และตัวอย่างที่ 2 เป็น normal
- โมเดล K-Nearest Neighbours (K-NN) ทำนายคำตอบออกมาว่าข้อมูลใหม่ทั้งสองตัวอย่างเป็น spam ทั้งคู่
- โมเดล Neural Network ก็ทำนายคำตอบออกมาว่าข้อมูลใหม่ทั้งสองตัวอย่างเป็น spam ทั้งคู่
จากผลการทำนายของท้ังสามโมเดลเราจะได้ว่า ข้อมูลใหม่ตัวอย่างที่ 1 จะตอบเป็น spam เนื่องจากทั้ง 3 โมเดลตอบเหมือนกันว่าเป็น spam แต่ข้อมูลใหม่ตัวอย่างที่ 2 จะตอบเป็น spam เนื่องจาก 2 ใน 3 โมเดลตอบตรงกันว่าเป็น spam
2. Bootstrap Aggregating (Bagging)
วิธีการที่สองนี้แตกต่างจากวิธีการ Vote Ensemble โดยการสร้างโมเดลที่หลากหลายนั้นใช้การสุ่มข้อมูลตัวอย่างจากเทรนนิ่ง ดาต้า ออกมาเป็นหลายๆ ชุด (แทนที่จะใช้ข้อมูลเทรนนิ่ง ดาต้าทั้งหมดแบบวิธีการ Vote Ensemble) แต่ใช้การสร้างโมเดลด้วยเทคนิค classification เดียวกัน เช่น ใช้เทคนิค Decision Tree หรือ เทคนิค Neural Networks ทั้งหมด ดังแสดงในรูปด้านล่าง ซึ่งใช้เทคนิค Decision Tree ทั้งสามโมเดลครับ แม้ว่าจะเป็นเทคนิค Decision Tree เหมือนกันแต่ข้อมูลที่ใช้ในการสร้างโมเดลต่างกันก็ทำให้โมเดลที่สร้างขึ้นมาได้มีลักษณะที่ต่างๆ กันด้วย

ในลักษณะเดียวกันหลังจากที่สร้างโมเดล Bagging ด้วยเทคนิค Decision Tree ได้แล้ว ขั้นตอนถัดไป คือ การนำโมเดลที่สร้างได้ไปทำนายข้อมูลใหม่ ดังแสดงในรูปด้านล่าง
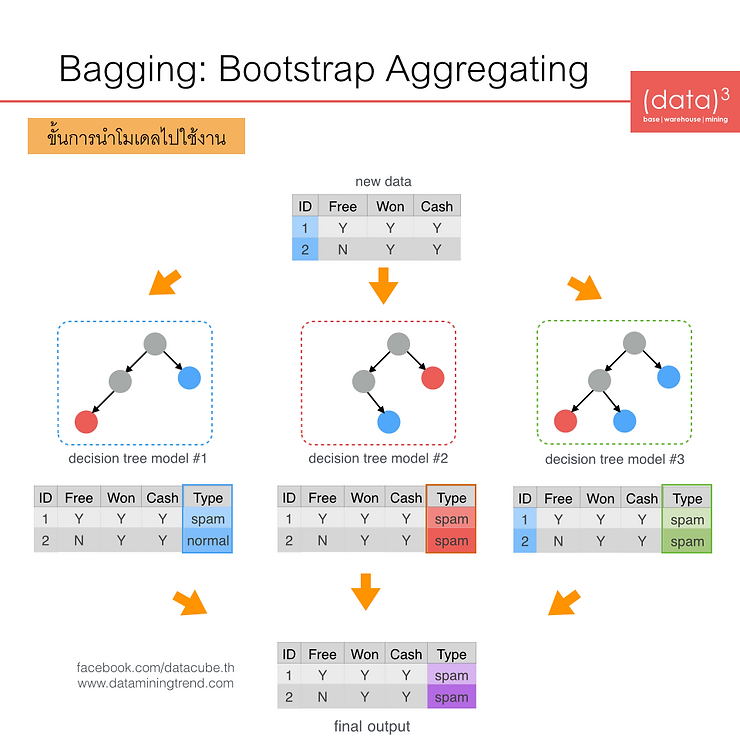
จากรูปจะมีข้อมูลใหม่ (new data) ที่ยังไม่รู้คลาสคำตอบ 2 ตัวอย่าง (example) ซึ่ง
- โมเดล Decision Tree (โมเดลที่ 1) ทำนายคำตอบออกมาว่าข้อมูลใหม่ตัวอย่างที่ 1 เป็น spam และตัวอย่างที่ 2 เป็น normal
- โมเดล Decision Tree (โมเดลที่ 2) ทำนายคำตอบออกมาว่าข้อมูลใหม่ทั้งสองตัวอย่างเป็น spam ทั้งคู่
- โมเดล Decision Tree (โมเดลที่ 3) ก็ทำนายคำตอบออกมาว่าข้อมูลใหม่ทั้งสองตัวอย่างเป็น spam ทั้งคู่
จากผลการทำนายของท้ังสามโมเดลเราจะได้ว่า ข้อมูลใหม่ตัวอย่างที่ 1 จะตอบเป็น spam เนื่องจากทั้ง 3 โมเดลตอบเหมือนกันว่าเป็น spam แต่ข้อมูลใหม่ตัวอย่างที่ 2 จะตอบเป็น spam เนื่องจาก 2 ใน 3 โมเดลตอบตรงกันว่าเป็น spam ครับ
3. Random Forest
เป็นวิธีการที่คล้ายกับ Bagging มากแต่เพิ่มการสร้างความหลากหลายของโมเดลด้วยการสุ่มแอตทริบิวต์ด้วยแทนที่จะเป็นการสุ่มเฉพาะข้อมูลตัวอย่างเพียงอย่างเดียวเหมือน Bagging ครับ และเทคนิคที่ใช้ในการสร้างโมเดลก็เป็นเพียงแค่ Decision Tree อย่างเดียวครับ ดังแสดงในรูปด้านล่าง ซึ่งมีการสุ่มแอตทริบิวต์ต่างๆ กันโดย
- เทรนนิ่ง ดาต้าชุดที่ 1 ใช้แอตทริบิวต์สองตัว คือ แอตทริบิวต์ Free และ Cash
- เทรนนิ่ง ดาต้าชุดที่ 2 ใช้แอตทริบิวต์สองตัว คือ แอตทริบิวต์ Won และ Cash
- เทรนนิ่ง ดาต้าชุดที่ 3 ใช้แอตทริบิวต์สองตัว คือ แอตทริบิวต์ Free และ Won
แม้ว่าจะเป็นเทคนิค Decision Tree เหมือนกันแต่ข้อมูลและแอตทริบิวต์ที่ใช้ในการสร้างโมเดลต่างกันก็ทำให้โมเดลที่สร้างขึ้นมาได้มีลักษณะที่ต่างๆ กันด้วย

ในลักษณะเดียวกันหลังจากที่สร้างโมเดล Bagging ด้วยเทคนิค Decision Tree ได้แล้ว ขั้นตอนถัดไป คือ การนำโมเดลที่สร้างได้ไปทำนายข้อมูลใหม่ ดังแสดงในรูปด้านล่าง

จากรูปจะมีข้อมูลใหม่ (new data) ที่ยังไม่รู้คลาสคำตอบ 2 ตัวอย่าง (example) ซึ่ง
- โมเดล Decision Tree (โมเดลที่ 1) ทำนายคำตอบออกมาว่าข้อมูลใหม่ตัวอย่างที่ 1 เป็น spam และตัวอย่างที่ 2 เป็น normal
- โมเดล Decision Tree (โมเดลที่ 2) ทำนายคำตอบออกมาว่าข้อมูลใหม่ทั้งสองตัวอย่างเป็น spam ทั้งคู่ครับ
- โมเดล Decision Tree (โมเดลที่ 3) ก็ทำนายคำตอบออกมาว่าข้อมูลใหม่ทั้งสองตัวอย่างเป็น spam ทั้งคู่
ที่มา. http://dataminingtrend.com
ฐานข้อมูล
ฐานข้อมูลคือ ฐานข้อมูลที่มีค่าขนาดใหญ่มากในปริมาณเก็บข้อมูลในความซับซ้อนทั้งหมดได้เพื่อรักษาความเป็นส่วนตัวประกอบด้วยข้อมูลที่ไม่สามรถถูกแทนที่ได้ต้องสมบูรณ์ครอบคลุมและถูกต้องสำหรับผู้ใช้อินเทอร์เน็ต
ฐานข้อมูล (Database)
ข้อมูล คือ ข้อเท็จจริงของสิ่งที่เราสนใจ ข้อเท็จจริงที่เป็นตัวเลข ข้อความ หรือรายละเอียดซึ่งอาจอยู่ในรูปแบบต่าง ๆ เช่น ภาพ เสียง วีดิโอไม่ว่าจะเป็นคน สัตว์ สิ่งของ หรือเหตุการณ์ที่เกี่ยวข้องกับสิ่งต่าง ๆ ข้อมูลเป็นเรื่องเกี่ยวกับเหตุการณ์ที่เกิดขึ้นอย่างต่อเนื่อง และต้องถูกต้องแม่นยำ ครบถ้วน ขึ้นอยู่กับผู้ดำเนินการที่ให้ความสำคัญของความรวดเร็วของการเก็บข้อมูล ดังนั้นการเก็บข้อมูลจึงเป็นการเก็บรวบรวมเกี่ยวกับข้อเท็จจริงของสิ่งที่เราสนใจนั่นเอง ข้อมูลจึงหมายถึงตัวแทนของข้อเท็จจริง หรือความเป็นไปของสิ่งของที่เราสนใจ
Database หรือ ฐานข้อมูล คือ กลุ่มของข้อมูลที่ถูกเก็บรวบรวมไว้ โดยมีความสัมพันธ์ซึ่งกันและกัน โดยไม่ได้บังคับว่าข้อมูลทั้งหมดนี้จะต้องเก็บไว้ในแฟ้มข้อมูลเดียวกันหรือแยกเก็บหลาย ๆ แฟ้มข้อมูล
ระบบฐานข้อมูล (Database System) คือ ระบบที่รวบรวมข้อมูลต่าง ๆ ที่เกี่ยวข้องกันเข้าไว้ด้วยกันอย่างมีระบบมีความสัมพันธ์ระหว่างข้อมูลต่าง ๆ ที่ชัดเจน ในระบบฐานข้อมูลจะประกอบด้วยแฟ้มข้อมูลหลายแฟ้มที่มีข้อมูล เกี่ยวข้องสัมพันธ์กันเข้าไว้ด้วยกันอย่างเป็นระบบและเปิดโอกาสให้ผู้ใช้สามารถใช้งานและดูแลรักษาป้องกันข้อมูลเหล่านี้ ได้อย่างมีประสิทธิภาพ
ข้อมูล หรือการตั้งคำถามเพื่อให้ได้ข้อมูลมา โดยผู้ใช้ไม่จำเป็นต้องรับรู้เกี่ยวกับรายละเอียดภายในโครงสร้างของฐานข้อมูล
ลักษณะข้อมูลในฐานข้อมูล
ระบบฐานข้อมูล (Database System) หมายถึง โครงสร้างสารสนเทศที่ประกอบด้วยรายละเอียดของข้อมูลที่เกี่ยวข้องกันที่จะนำมาใช้ในระบบต่าง ๆ ร่วมกัน
ฐานข้อมูลเป็นการจัดเก็บข้อมูลอย่างเป็นระบบ ทำให้ผู้ใช้สามารถใช้ข้อมูลที่เกี่ยวข้องในระบบงานต่าง ๆ ร่วมกันได้ โดยที่จะไม่เกิดความซ้ำซ้อนของข้อมูล และยังสามารถหลีกเลี่ยงความขัดแย้งของข้อมูลด้วย อีกทั้งข้อมูลในระบบก็จะถูกต้องเชื่อถือได้ และเป็นมาตรฐานเดียวกัน โดยจะมีการกำหนดระบบความปลอดภัยของข้อมูลขึ้น
1.ฐานข้อมูลเชิงสัมพันธ์ (Relational Database) เป็นการเก็บข้อมูลในรูปแบบที่เป็นตาราง (Table)หรือเรียกว่า รีเลชั่น (Relation) มีลักษณะเป็น 2 มิติ คือเป็นแถว (row) และเป็นคอลัมน์ (column) การเชื่อมโยงข้อมูลระหว่างตาราง จะเชื่อมโยงโดยใช้แอททริบิวต์ (attribute) หรือคอลัมน์ที่เหมือนกันทั้งสองตารางเป็นตัวเชื่อมโยงข้อมูล ฐานข้อมูลเชิงสัมพันธ์นี้จะเป็นรูปแบบของฐานข้อมูลที่นิยมใช้ในปัจจุบัน
2. ฐานข้อมูลแบบเครือข่าย (Network Database)ฐานข้อมูลแบบเครือข่ายจะเป็นการรวมระเบียนต่าง ๆ และความสัมพันธ์ระหว่างระเบียนแต่จะต่างกับฐานข้อมูลเชิงสัมพันธ์ คือ ในฐานข้อมูลเชิงสัมพันธ์จะแฝงความสัมพันธ์เอาไว้ โดยระเบียนที่มีความสัมพันธ์กันจะต้องมีค่าของข้อมูลในแอททริบิวต์ใดแอททริบิวต์หนึ่งเหมือนกัน แต่ฐานข้อมูลแบบเครือข่าย จะแสดงความสัมพันธ์อย่างชัดเจน ตัวอย่างเช่น
3. ฐานข้อมูลแบบลำดับชั้น (Hierarchical Database)ฐานข้อมูลแบบลำดับชั้น เป็นโครงสร้างที่จัดเก็บข้อมูลในลักษณะความสัมพันธ์แบบพ่อ-ลูก (Parent-Child Relationship Type : PCR Type) หรือเป็นโครงสร้างรูปแบบต้นไม้ (Tree) ข้อมูลที่จัดเก็บในที่นี้ คือ ระเบียน (Record) ซึ่งประกอบด้วยค่าของเขตข้อมูล (Field) ของเอนทิตี้หนึ่ง ๆ ฐานข้อมูลแบบลำดับชั้นนี้คล้ายคลึงกับฐานข้อมูลแบบเครือข่าย แต่ต่างกันที่ฐานข้อมูลแบบลำดับชั้น มีกฎเพิ่มขึ้นมาอีกหนึ่งประการ คือ ในแต่ละกรอบจะมีลูกศรวิ่งเข้าหาได้ไม่เกิน 1หัวลูกศร
ประโยชน์ของฐานข้อมูล
1. ลดการเก็บข้อมูลที่ซ้ำซ้อน ข้อมูลบางชุดที่อยู่ในรูปของแฟ้มข้อมูลอาจมีปรากฏอยู่หลาย ๆ แห่ง เพราะมีผู้ใช้ข้อมูลชุดนี้หลายคน เมื่อ
ใช้ระบบฐานข้อมูลแล้วจะช่วยให้ความซ้ำซ้อนของข้อมูลลดน้อยลง
2. รักษาความถูกต้องของข้อมูล เนื่องจากฐานข้อมูลมีเพียงฐานข้อมูลเดียว ในกรณีที่มีข้อมูลชุดเดียวกันปรากฏอยู่หลายแห่งในฐานข้อมูล ข้อมูลเหล่านี้จะต้องตรงกัน ถ้ามีการแก้ไขข้อมูลนี้ทุก ๆ แห่งที่ข้อมูลปรากฏอยู่จะแก้ไขให้ถูกต้องตามกันหมดโดยอัตโนมัติด้วยระบบจัดการฐานข้อมูล
3. การป้องกันและรักษาความปลอดภัยให้กับข้อมูลทำได้อย่างสะดวก การป้องกันและรักษาความปลอดภัยกับข้อมูลระบบฐานข้อมูลจะให้เฉพาะผู้ที่เกี่ยวข้องเท่านั้น ซึ่งก่อให้เกิดความปลอดภัย(security)ของข้อมูลด้วย

ที่มา. https://sites.google.com
ไม่มีความคิดเห็น:
แสดงความคิดเห็น